This is the third part of the Bash One-Liners Explained article series. In this part I'll teach you all about input/output redirection. I'll use only the best bash practices, various bash idioms and tricks. I want to illustrate how to get various tasks done with just bash built-in commands and bash programming language constructs.
See the first part of the series for introduction. After I'm done with the series I'll release an ebook (similar to my ebooks on awk, sed, and perl), and also bash1line.txt (similar to my perl1line.txt).
Also see my other articles about working fast in bash from 2007 and 2008:
- Working Productively in Bash's Emacs Command Line Editing Mode (comes with a cheat sheet)
- Working Productively in Bash's Vi Command Line Editing Mode (comes with a cheat sheet)
- The Definitive Guide to Bash Command Line History (comes with a cheat sheet)
Let's start.
Part III: Redirections
Working with redirections in bash is really easy once you realize that it's all about manipulating file descriptors. When bash starts it opens the three standard file descriptors: stdin (file descriptor 0), stdout (file descriptor 1), and stderr (file descriptor 2). You can open more file descriptors (such as 3, 4, 5, ...), and you can close them. You can also copy file descriptors. And you can write to them and read from them.
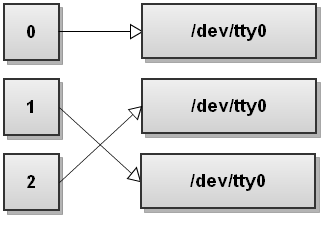
File descriptors always point to some file (unless they're closed). Usually when bash starts all three file descriptors, stdin, stdout, and stderr, point to your terminal. The input is read from what you type in the terminal and both outputs are sent to the terminal.
Assuming your terminal is /dev/tty0, here is how the file descriptor table looks like when bash starts:
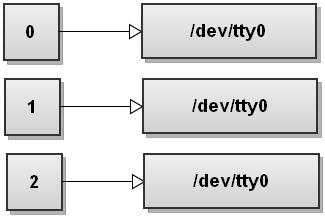
When bash runs a command it forks a child process (see man 2 fork) that inherits all the file descriptors from the parent process, then it sets up the redirections that you specified, and execs the command (see man 3 exec).
To be a pro at bash redirections all you need to do is visualize how the file descriptors get changed when redirections happen. The graphics illustrations will help you.
1. Redirect the standard output of a command to a file
$ command >file
Operator > is the output redirection operator. Bash first tries to open the file for writing and if it succeeds it sends the stdout of command to the newly opened file. If it fails opening the file, the whole command fails.
Writing command >file is the same as writing command 1>file. The number 1 stands for stdout, which is the file descriptor number for standard output.
Here is how the file descriptor table changes. Bash opens file and replaces file descriptor 1 with the file descriptor that points to file. So all the output that gets written to file descriptor 1 from now on ends up being written to file:
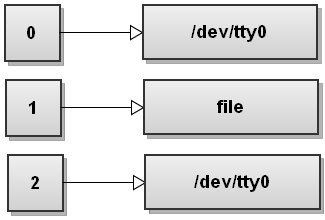
In general you can write command n>file, which will redirect the file descriptor n to file.
For example,
$ ls > file_list
Redirects the output of the ls command to the file_list file.
2. Redirect the standard error of a command to a file
$ command 2> file
Here bash redirects the stderr to file. The number 2 stands for stderr.
Here is how the file descriptor table changes:
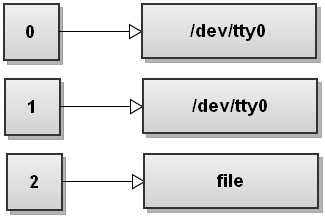
Bash opens file for writing, gets the file descriptor for this file, and it replaces file descriptor 2 with the file descriptor of this file. So now anything written to stderr gets written to file.
3. Redirect both standard output and standard error to a file
$ command &>file
This one-liner uses the &> operator to redirect both output streams - stdout and stderr - from command to file. This is bash's shortcut for quickly redirecting both streams to the same destination.
Here is how the file descriptor table looks like after bash has redirected both streams:
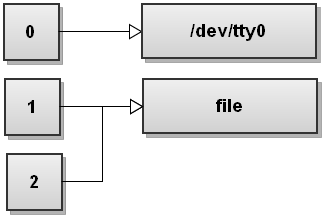
As you can see both stdout and stderr now point to file. So anything written to stdout and stderr gets written to file.
There are several ways to redirect both streams to the same destination. You can redirect each stream one after another:
$ command >file 2>&1
This is a much more common way to redirect both streams to a file. First stdout is redirected to file, and then stderr is duplicated to be the same as stdout. So both streams end up pointing to file.
When bash sees several redirections it processes them from left to right. Let's go through the steps and see how that happens. Before running any commands bash's file descriptor table looks like this:
Now bash processes the first redirection >file. We've seen this before and it makes stdout point to file:
Next bash sees the second redirection 2>&1. We haven't seen this redirection before. This one duplicates file descriptor 2 to be a copy of file descriptor 1 and we get:
Both streams have been redirected to file.
However be careful here! Writing:
command >file 2>&1
Is not the same as writing:
$ command 2>&1 >file
The order of redirects matters in bash! This command redirects only the standard output to the file. The stderr will still print to the terminal. To understand why that happens, let's go through the steps again. So before running the command the file descriptor table looks like this:
Now bash processes redirections left to right. It first sees 2>&1 so it duplicates stderr to stdout. The file descriptor table becomes:
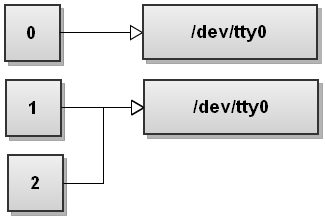
Now bash sees the second redirect >file and it redirects stdout to file:
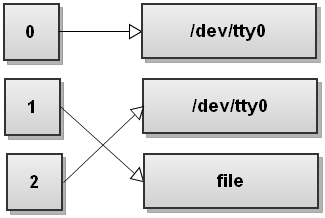
Do you see what happens here? Stdout now points to file but the stderr still points to the terminal! Everything that gets written to stderr still gets printed out to the screen! So be very, very careful with the order of redirects!
Also note that in bash, writing this:
$ command &>file
Is exactly the same as:
$ command >&file
The first form is preferred however.
4. Discard the standard output of a command
$ command > /dev/null
The special file /dev/null discards all data written to it. So what we're doing here is redirecting stdout to this special file and it gets discarded. Here is how it looks from the file descriptor table's perspective:
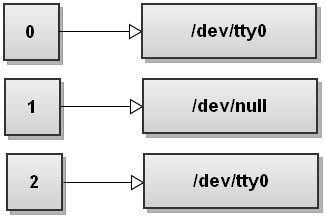
Similarly, by combining the previous one-liners, we can discard both stdout and stderr by doing:
$ command >/dev/null 2>&1
Or just simply:
$ command &>/dev/null
File descriptor table for this feat looks like this:
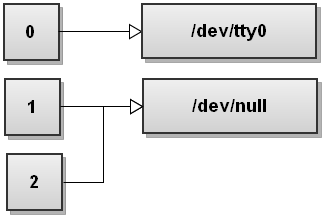
5. Redirect the contents of a file to the stdin of a command
$ command <file
Here bash tries to open the file for reading before running any commands. If opening the file fails, bash quits with error and doesn't run the command. If opening the file succeeds, bash uses the file descriptor of the opened file as the stdin file descriptor for the command.
After doing that the file descriptor table looks like this:
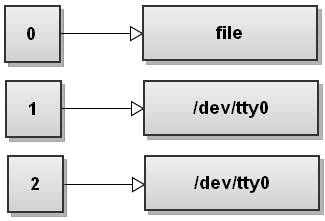
Here is an example. Suppose you want to read the first line of the file in a variable. You can simply do this:
$ read -r line < file
Bash's built-in read command reads a single line from standard input. By using the input redirection operator < we set it up to read the line from the file.
6. Redirect a bunch of text to the stdin of a command
$ command <<EOL your multi-line text goes here EOL
Here we use the here-document redirection operator <<MARKER. This operator instructs bash to read the input from stdin until a line containing only MARKER is found. At this point bash passes the all the input read so far to the stdin of the command.
Here is a common example. Suppose you've copied a bunch of URLs to the clipboard and you want to remove http:// part of them. A quick one-liner to do this would be:
$ sed 's|http://||' <<EOL http://url1.com http://url2.com http://url3.com EOL
Here the input of a list of URLs is redirected to the sed command that strips http:// from the input.
This example produces this output:
url1.com url2.com url3.com
7. Redirect a single line of text to the stdin of a command
$ command <<< "foo bar baz"
For example, let's say you quickly want to pass the text in your clipboard as the stdin to a command. Instead of doing something like:
$ echo "clipboard contents" | command
You can now just write:
$ command <<< "clipboard contents"
This trick changed my life when I learned it!
8. Redirect stderr of all commands to a file forever
$ exec 2>file $ command1 $ command2 $ ...
This one-liner uses the built-in exec bash command. If you specify redirects after it, then they will last forever, meaning until you change them or exit the script/shell.
In this case the 2>file redirect is setup that redirects the stderr of the current shell to the file. Running commands after setting up this redirect will have the stderr of all of them redirected to file. It's really useful in situations when you want to have a complete log of all errors that happened in the script, but you don't want to specify 2>file after every single command!
In general exec can take an optional argument of a command. If it's specified, bash replaces itself with the command. So what you get is only that command running, and there is no more shell.
9. Open a file for reading using a custom file descriptor
$ exec 3<file
Here we use the exec command again and specify the 3<file redirect to it. What this does is opens the file for reading and assigns the opened file-descriptor to the shell's file descriptor number 3. The file descriptor table now looks like this:
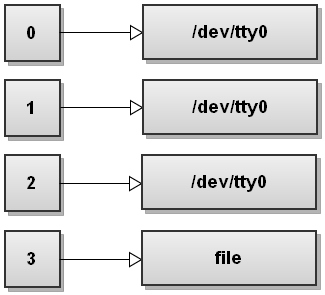
Now you can read from the file descriptor 3, like this:
$ read -u 3 line
This reads a line from the file that we just opened as fd 3.
Or you can use regular shell commands such as grep and operate on file descriptor 3:
$ grep "foo" <&3
What happens here is file descriptor 3 gets duplicated to file descriptor 1 - stdin of grep. Just remember that once you read the file descriptor it's been exhausted and you need to close it and open it again to use it. (You can't rewind an fd in bash.)
After you're done using fd 3, you can close it this way:
$ exec 3>&-
Here the file descriptor 3 is duped to -, which is bash's special way to say "close this fd".
10. Open a file for writing using a custom file descriptor
$ exec 4>file
Here we simply tell bash to open file for writing and assign it number 4. The file descriptor table looks like this:
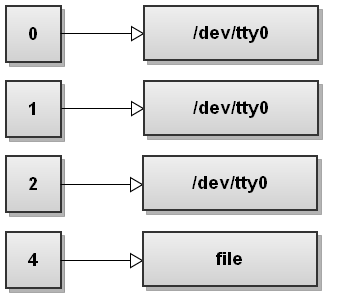
As you can see file descriptors don't have to be used in order, you can open any file descriptor number you like from 0 to 255.
Now we can simply write to the file descriptor 4:
$ echo "foo" >&4
And we can close the file descriptor 4:
$ exec 4>&-
It's so simple now once we learned how to work with custom file descriptors!
11. Open a file both for writing and reading
$ exec 3<>file
Here we use bash's diamond operator <>. The diamond operator opens a file descriptor for both reading and writing.
So for example, if you do this:
$ echo "foo bar" > file # write string "foo bar" to file "file". $ exec 5<> file # open "file" for rw and assign it fd 5. $ read -n 3 var <&5 # read the first 3 characters from fd 5. $ echo $var
This will output foo as we just read the first 3 chars from the file.
Now we can write some stuff to the file:
$ echo -n + >&5 # write "+" at 4th position. $ exec 5>&- # close fd 5. $ cat file
This will output foo+bar as we wrote the + char at 4th position in the file.
12. Send the output from multiple commands to a file
$ (command1; command2) >file
This one-liner uses the (commands) construct that runs the commands a sub-shell. A sub-shell is a child process launched by the current shell.
So what happens here is the commands command1 and command2 get executed in the sub-shell, and bash redirects their output to file.
13. Execute commands in a shell through a file
Open two shells. In shell 1 do this:
mkfifo fifo exec < fifo
In shell 2 do this:
exec 3> fifo; echo 'echo test' >&3
Now take a look in shell 1. It will execute echo test. You can keep writing commands to fifo and shell 1 will keep executing them.
Here is how it works.
In shell 1 we use the mkfifo command to create a named pipe called fifo. A named pipe (also called a FIFO) is similar to a regular pipe, except that it's accessed as part of the file system. It can be opened by multiple processes for reading or writing. When processes are exchanging data via the FIFO, the kernel passes all data internally without writing it to the file system. Thus, the FIFO special file has no contents on the file system; the file system entry merely serves as a reference point so that processes can access the pipe using a name in the file system.
Next we use exec < fifo to replace current shell's stdin with fifo.
Now in shell 2 we open the named pipe for writing and assign it a custom file descriptor 3. Next we simply write echo test to the file descriptor 3, which goes to fifo.
Since shell 1's stdin is connected to this pipe it executes it! Really simple!
14. Access a website through bash
$ exec 3<>/dev/tcp/www.google.com/80 $ echo -e "GET / HTTP/1.1\n\n" >&3 $ cat <&3
Bash treats the /dev/tcp/host/port as a special file. It doesn't need to exist on your system. This special file is for opening tcp connections through bash.
In this example we first open file descriptor 3 for reading and writing and point it to /dev/tcp/www.google.com/80 special file, which is a connection to www.google.com on port 80.
Next we write GET / HTTP/1.1\n\n to file descriptor 3. And then we simply read the response back from the same file descriptor by using cat.
Similarly you can create a UDP connection through /dev/udp/host/port special file.
With /dev/tcp/host/port you can even write things like port scanners in bash!
15. Prevent overwriting the contents of a file when redirecting output
$ set -o noclobber
This turns on the noclobber option for the current shell. The noclobber option prevents you from overwriting existing files with the > operator.
If you try redirecting output to a file that exists, you'll get an error:
$ program > file bash: file: cannot overwrite existing file
If you're 100% sure that you want to overwrite the file, use the >| redirection operator:
$ program >| file
This succeeds as it overrides the noclobber option.
16. Redirect standard input to a file and print it to standard output
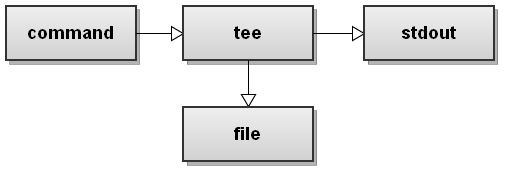
$ command | tee file
The tee command is super handy. It's not part of bash but you'll use it often. It takes an input stream and prints it both to standard output and to a file.
In this example it takes the stdout of command, puts it in file, and prints it to stdout.
Here is a graphical illustration of how it works:
17. Send stdout of one process to stdin of another process
$ command1 | command2
This is simple piping. I'm sure everyone is familiar with this. I'm just including it here for completeness. Just to remind you, a pipe connects stdout of command1 with the stdin of command2.
It can be illustrated with a graphic:
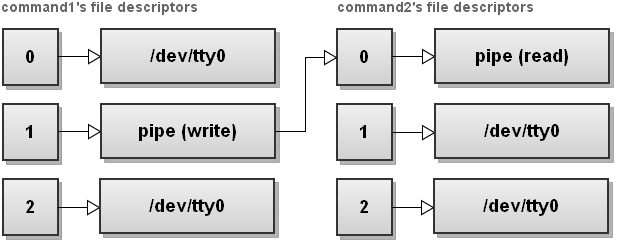
As you can see, everything sent to file descriptor 1 (stdout) of command1 gets redirected through a pipe to file descriptor 0 (stdin) of command2.
You can read more about pipes in man 2 pipe.
18. Send stdout and stderr of one process to stdin of another process
$ command1 |& command2
This works on bash versions starting 4.0. The |& redirection operator sends both stdout and stderr of command1 over a pipe to stdin of command2.
As the new features of bash 4.0 aren't widely used, the old, and more portable way to do the same is:
$ command1 2>&1 | command2
Here is an illustration that shows what happens with file descriptors:
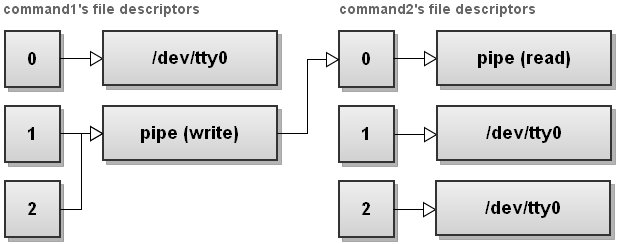
First command1's stderr is redirected to stdout, and then a pipe is setup between command1's stdout and command2's stdin.
19. Give file descriptors names
$ exec {filew}>output_file
Named file descriptors is a feature of bash 4.1. Named file descriptors look like {varname}. You can use them just like regular, numeric, file descriptors. Bash internally chooses a free file descriptor and assigns it a name.
20. Order of redirections
You can put the redirections anywhere in the command you want. Check out these 3 examples, they all do the same:
$ echo hello >/tmp/example $ echo >/tmp/example hello $ >/tmp/example echo hello
Got to love bash!
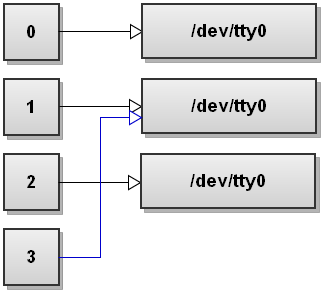
21. Swap stdout and stderr
$ command 3>&1 1>&2 2>&3
Here we first duplicate file descriptor 3 to be a copy of stdout. Then we duplicate stdout to be a copy of stderr, and finally we duplicate stderr to be a copy of file descriptor 3, which is stdout. As a result we've swapped stdout and stderr.
Let's go through each redirection with illustrations. Before running the command, we've file descriptors pointing to the terminal:
Next bash setups 3>&1 redirection. This creates file descriptor 3 to be a copy of file descriptor 1:
Next bash setups 1>&2 redirection. This makes file descriptor 1 to be a copy of file descriptor 2:
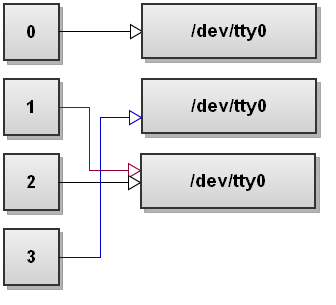
Next bash setups 2>&3 redirection. This makes file descriptor 2 to be a copy of file descriptor 3:

If we want to be nice citizens we can also close file descriptor 3 as it's no longer needed:
$ command 3>&1 1>&2 2>&3 3>&-
The file descriptor table then looks like this:
As you can see, file descriptors 1 and 2 have been swapped.
22. Send stdout to one process and stderr to another process
$ command > >(stdout_cmd) 2> >(stderr_cmd)
This one-liner uses process substitution. The >(...) operator runs the commands in ... with stdin connected to the read part of an anonymous named pipe. Bash replaces the operator with the filename of the anonymous pipe.
So for example, the first substitution >(stdout_cmd) might return /dev/fd/60, and the second substitution might return /dev/fd/61. Both of these files are named pipes that bash created on the fly. Both named pipes have the commands as readers. The commands wait for someone to write to the pipes so they can read the data.
The command then looks like this:
$ command > /dev/fd/60 2> /dev/fd/61
Now these are just simple redirections. Stdout gets redirected to /dev/fd/60, and stderr gets redirected to /dev/fd/61.
When the command writes to stdout, the process behind /dev/fd/60 (process stdout_cmd) reads the data. And when the command writes to stderr, the process behind /dev/fd/61 (process stderr_cmd) reads the data.
23. Find the exit codes of all piped commands
Let's say you run several commands all piped together:
$ cmd1 | cmd2 | cmd3 | cmd4
And you want to find out the exit status codes of all these commands. How do you do it? There is no easy way to get the exit codes of all commands as bash returns only the exit code of the last command.
Bash developers thought about this and they added a special PIPESTATUS array that saves the exit codes of all the commands in the pipe stream.
The elements of the PIPESTATUS array correspond to the exit codes of the commands. Here's an example:
$ echo 'pants are cool' | grep 'moo' | sed 's/o/x/' | awk '{ print $1 }'
$ echo ${PIPESTATUS[@]}
0 1 0 0
In this example grep 'moo' fails, and the 2nd element of the PIPESTATUS array indicates failure.
Shoutouts
Shoutouts to bash hackers wiki for their illustrated redirection tutorial and bash version changes.
Enjoy!
Enjoy the article and let me know in the comments what you think about it! If you think that I forgot some interesting bash one-liners related to redirections, let me know in the comments below!